The other day, I saw a TikTok of someone searching 2.7 million NDJSON records in Python. It took about 4 seconds using a fancy C-bound library.
I figured I could do better. Would it be more work than just plopping in a library? Sure. Great learning exercise, though!
(tldr: 30x faster indeed!)
First, what the heck is NDJSON? #
NDJSON stands for newline-delimited JSON. Essentially, instead of a JSON array looking like:
1[
2 {
3 "id": "1"
4 },
5 {
6 "id": "2"
7 },
8]
NDJSON stores each item on a new line, making it easy to parse line by line:
1{"id": 1}
2{"id": 2}
The Challenge #
I had a ~5GB file: 2.7 million newline-delimited JSON (NDJSON) records. Each line was a complete JSON object with fields like categories, id, title, etc. (the dataset is the arXiv Dataset)
For clarity, here is a line (parsed into regular JSON for your reading pleasure):
1{
2 "id":"0704.0010",
3 "submitter":"Sergei Ovchinnikov",
4 "authors":"Sergei Ovchinnikov",
5 "title":"Partial cubes: structures, characterizations, and constructions",
6 "comments":"36 pages, 17 figures",
7 "journal-ref":null,
8 "doi":null,
9 "report-no":null,
10 "categories":"math.CO",
11 "license":null,
12 "abstract":"Partial cubes are isometric subgraphs of hypercubes. Structures on a graph\ndefined by means of semicubes, and Djokovi\\'{c}'s and Winkler's relations play\nan important role in the theory of partial cubes. These structures are employed\nin the paper to characterize bipartite graphs and partial cubes of arbitrary\ndimension. New characterizations are established and new proofs of some known\nresults are given.\n The operations of Cartesian product and pasting, and expansion and\ncontraction processes are utilized in the paper to construct new partial cubes\nfrom old ones. In particular, the isometric and lattice dimensions of finite\npartial cubes obtained by means of these operations are calculated.\n",
13 "versions":[{"version":"v1","created":"Sat, 31 Mar 2007 05:10:16 GMT"}],
14 "update_date":"2007-05-23",
15 "authors_parsed":[["Ovchinnikov","Sergei",""]]
16}
The Naive Approach #
My first version looked like what you’d expect: use Go's encoding/json package to unmarshal each line into a map[string]interface{} and check the value. I really just wanted to get a good "baseline" of what this looks like in Go:
1for {
2 line, err := reader.ReadBytes('\n')
3 if err != nil {
4 break
5 }
6
7 var obj map[string]interface{}
8 if err := json.Unmarshal(line, &obj); err != nil {
9 continue
10 }
11
12 if val, ok := obj[searchKey]; ok {
13 if str, ok := val.(string); ok && strings.Contains(str, searchValue) {
14 matches++
15 }
16 }
17}
And hey, it works! It just takes.. 33 seconds.
1$ time go run cmd/naive/main.go ./demo/arxiv-metadata-oai-snapshot.json categories hep
2Naive scan found 369868 matches
3go run cmd/naive/main.go ./demo/arxiv-metadata-oai-snapshot.json categories 33.37s user 2.28s system 102% cpu 34.701 total
Many Hours of Staring at pprof #
Go's built-in performance analysis tools are some of the best I've used. In all honesty, though, I was not expecting to get NEARLY the results I did, so I lost many iterations of my codebase. In short, it was a bunch of looking at flame charts and optimizing the code until it was blazing fast.
Nobody (well.. minus me.. and probably you.. ya nerd) likes looking at flame charts, so I'll "leave it out" (aka I forgot to take screenshots).
Enter Iteration v8293.1239.123-copy-final-rev-2-save #
After way too many flame charts and pprof runs, Jetson (its code name) hit peak velocity. The following is a test, where I set it to count every item where the categories contains hep (369,868 matches)
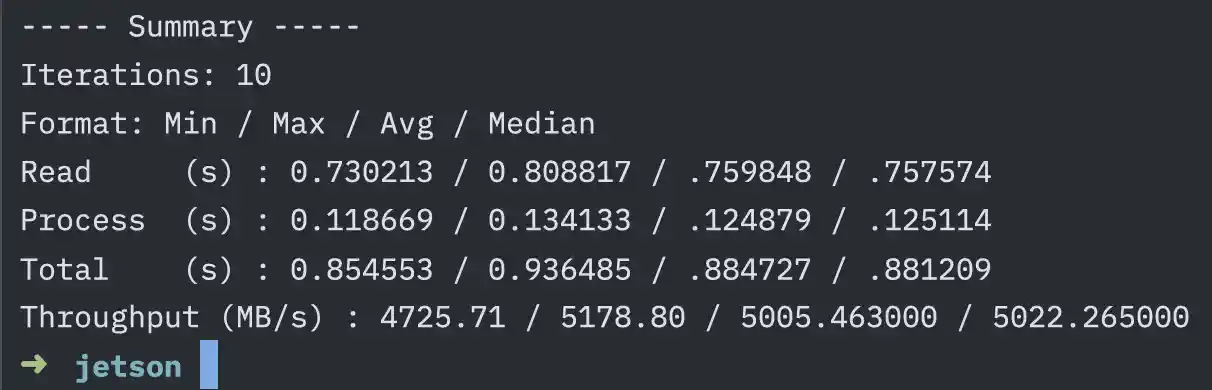
759ms average read, 124ms average processing, 884ms average total, at a throughput of 5,005 MB/s
Explaining these numbers a tad further..
- Average Read: this is how much time it takes for the SSD to read the data from the disk into memory (yup, all at once for concurrency + future ideas).
- Average Processing: this is how much time it takes for Jetson to search the data.
- Average Total: this is how much time it takes for Jetson to read the data from the disk into memory and process it.
- Average Throughput: this is how much data Jetson can process in a given time.
Sidenote: this ran on 10 workers on an M1 Max.
The title said "Bottlenecked by My SSD — Not My Code" (oh, and that emdash.. my code doesn't support dashes, or commas, ssshhh tech debt). The test script (available on GitHub) called vmtouch prior to running the benchmark: this purged the cache. When the cache is live, Jetson got up to 6 GB/s!

1,284,561 matches, 119ms processing, at a throughput of 6,116 MB/s
(and notice how the speed is not impacted by the number of matches)
Now.. you might be wondering how Jetson achieved such blazing speed. The answer lies in its unique architecture and optimization techniques.
How'd Jetson Get So Fast? #
As a 10,000 foot overview, I wrote Jetson to be so fast by:
- Avoiding parsing JSON
- Working directly on raw bytes
- Avoiding allocations
- Splitting work across goroutines
- Using SIMD-accelerated
bytes.IndexByte - Doing zero extra work per line
Avoid Parsing JSON #
Most tools / methods (jq, json.Unmarshal, etc.) parse every field into memory, converting, in Go-speak, bytes into maps, strings, interfaces, etc. This adds CPU overhead, allocations, and garbage collection pressure. For Jetson, my end goal was: given a key, count all records that contain the requested value. This is then (in reality, unless trying to break) highly likely to succeed using a bunch more "simple" approach.
For each row, Jetson first finds the key's position using bytes.IndexByte. If " + key + ":" is found, it then moves on to finding the end index of the value using bytes.IndexByte again. Once the start and end indices are known, the value can be extracted and compared to the requested value.
While this makes things like nested children difficult, Jetson's approach allows for efficient processing of large NDJSON datasets without the overhead of parsing and converting data into Go types. In my opinion, this is a significant advantage when dealing with large datasets like logs: "How many of this IP hit the server?".
Work directly on raw bytes #
String operations allocate and require UTF-8 decoding. Raw []byte slicing is faster, zero-copy, and avoids conversions entirely. Jetson uses bytes.Index, bytes.IndexByte, and bytes.Contains, which operate at machine speed with zero transformation.
Avoid Allocations #
Memory allocation is expensive, especially millions of times (so are channels, FYI!). If I were to parse JSON into Go structs or maps for each record, it'd be 2.7M+ allocations. Ew.
Jetson slices into a single preloaded buffer and reuses everything. Result: ~30–40 allocations total for 2.7M records.
Split Work Across Goroutines #
Modern CPUs are multicore. When a file is read in, Jetson gets the size of the file, and then divides it into chunks. Each goroutine is assigned a chunk to process, while making sure that no goroutine reads the same byte twice, and no byte is left behind (a FUUU-n exercise in parallelism).
Each goroutine works independently, with no locking or shared state. Through this, I enabled near-linear scaling with CPU cores: the more you have, the faster you go.
Use SIMD-Accelerated bytes.IndexByte #
On x86-64 and ARM64, Go's bytes.IndexByte compiles to hand-written (!!) assembly that uses Single Instruction, Multiple Data (SIMD) instructions (like AVX2 or NEON) under the hood.
That means Jetson isn't just fast in Go; it's running at hardware-level vectorized search speed.
(and yeah.. I had no idea what SIMD was before today. Only after trying to write my own loop and having major slow downs did I learn!)
Do Zero Extra Work Per Line #
Every loop iteration is surgical. Jetson reads each line once, checks for a key match using raw offset math, and moves on. No regex. No map lookups. No secondary passes. It’s a hot loop with no fat, which is exactly why it clocks in under 130ms.
Also, when a match is found, Jetson immediately stops looking at the line: zero extra work per line.
Validating Jetson #
So.. talking talk is easy. Proving it? Also pretty simple, thanks to Go's pprof:
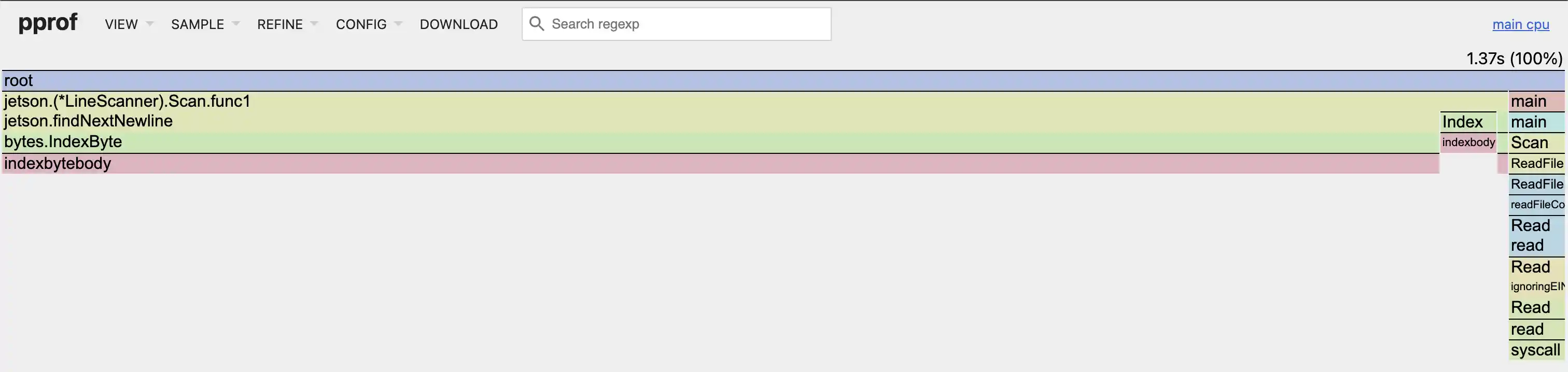
CPU Flame Graph showing indexbytebody being the only (real) "bottleneck"
This Flame Graph, like the memory one, is a testament to Jetson's efficiency. The #1 clock-time is indexbytebody, which is expected given its role in searching JSON data, but, as mentioned before, this function is already optimized to the max via hand-written (thanks, Go team!) assembly code + SIMD.
(to put the clock-time in perspective, that is ~480 nanoseconds per row)
Later on.. I want to start caching the positions of keys to allow for real-time CLI based searches. But for now, 1s total running time will be acceptable :)

Memory Heap Flame Graph showing only the os.ReadFile as a primary heap.
The chart explains itself. Really, 0 memory usage other than the os.ReadFile call itself. That being said, there were some allocs (~40 in benchmark tests) due to Go's handling of routines and a few other stdlib functions.
Lessons Learned #
- Channels aren't always good: I used channels a lot in the beginning, but after performance analysis, I had to throw them out. Still, if I ever add writing-out matches, I will use a channel. But, for the search process itself, there was too much overhead.
- Profiling > guessing: At a point, I stopped assuming what was "slow" and started measuring it. Using Go's built-in pprof, benchmem, and flame graphs, I found the real hotspots and trimmed everything else. Optimization without measurement is just luck: profiling made Jetson fast on purpose.
- Sometimes stdlib really is the fastest: SIMD is a great example of this. I ain't writing raw assembly better than a pro-assembler. Are you? NO (or probably not.. if you are.. nerd)!
- JQ is fast, Jetson was faster: Jetson was faster than JQ in this specific scenario, but JQ is still a powerful tool for JSON manipulation and querying. JQ got ~33 seconds for the same task.
Moving Forward #
There's always more, a project is never complete. That being said, I do have a few points to hit:
- Caching Key Positions: Implement caching mechanisms to store the positions of keys for faster lookups.
- Create a Real-Time CLI Search: Develop a CLI tool that allows users to search for specific keys in real-time.
- Allow for Arrays: Extend Jetson to handle arrays within JSON data, enabling more complex queries.
Play with it! #
All of the code is on github, you can install and run it super easy (it's go after all!):
$ go install github.com/kvizdos/jetson